
Introduction
We evaluate accelerators generated by Bambu on the standard benchmark suite MachSuite proposed in:
Brandon Reagen, Robert Adolf, Sophia Yakun Shao, Gu-Yeon Wei, and David Brooks. “MachSuite: Benchmarks for Accelerator Design and Customized Architectures.” 2014 IEEE International Symposium on Workload Characterization.
A comparison with a standard commercial HLS tool is provided when possible.
Setup
– Target hardware: AMD/Xilinx Virtex7 FPGA.
– Target frequency: 200 MHz.
– Source code for the benchmarks is available in examples/MachSuite.
Summary
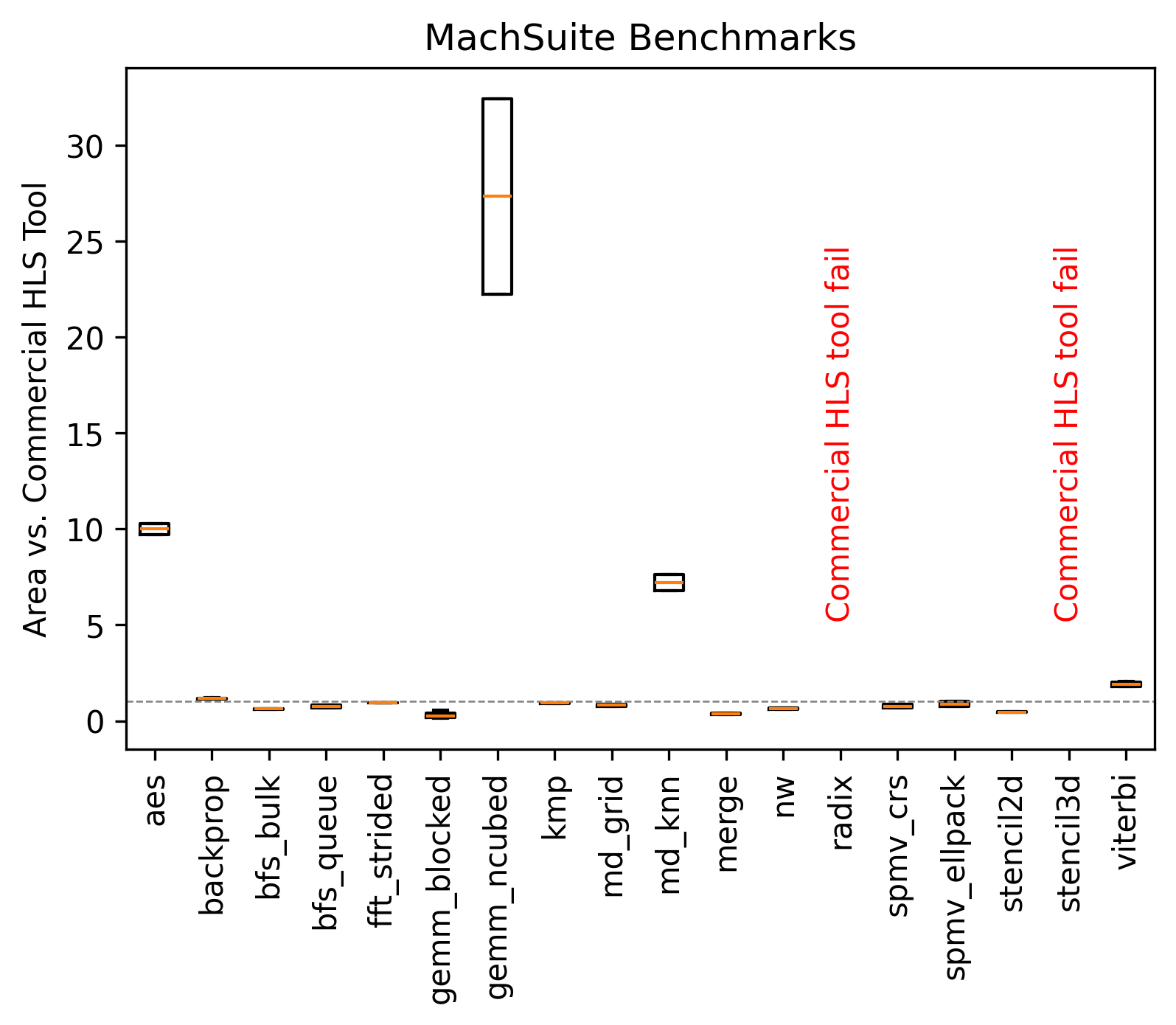
Speedup over commercial HLS tool for a set of different Bambu configurations across all benchmarks.
Latency is measured in ns (clock cycles * achieved period post-implementation). > 1 is better.

Area consumption over commercial HLS tool for a set of different Bambu configurations across all benchmarks.
Area is measured in Equivalent LUTs (BRAMs * 40 + DRAMs * 40 + DSPs * 40 + Registers * 0.5 + LUTs). < 1 is better.
Trade-offs
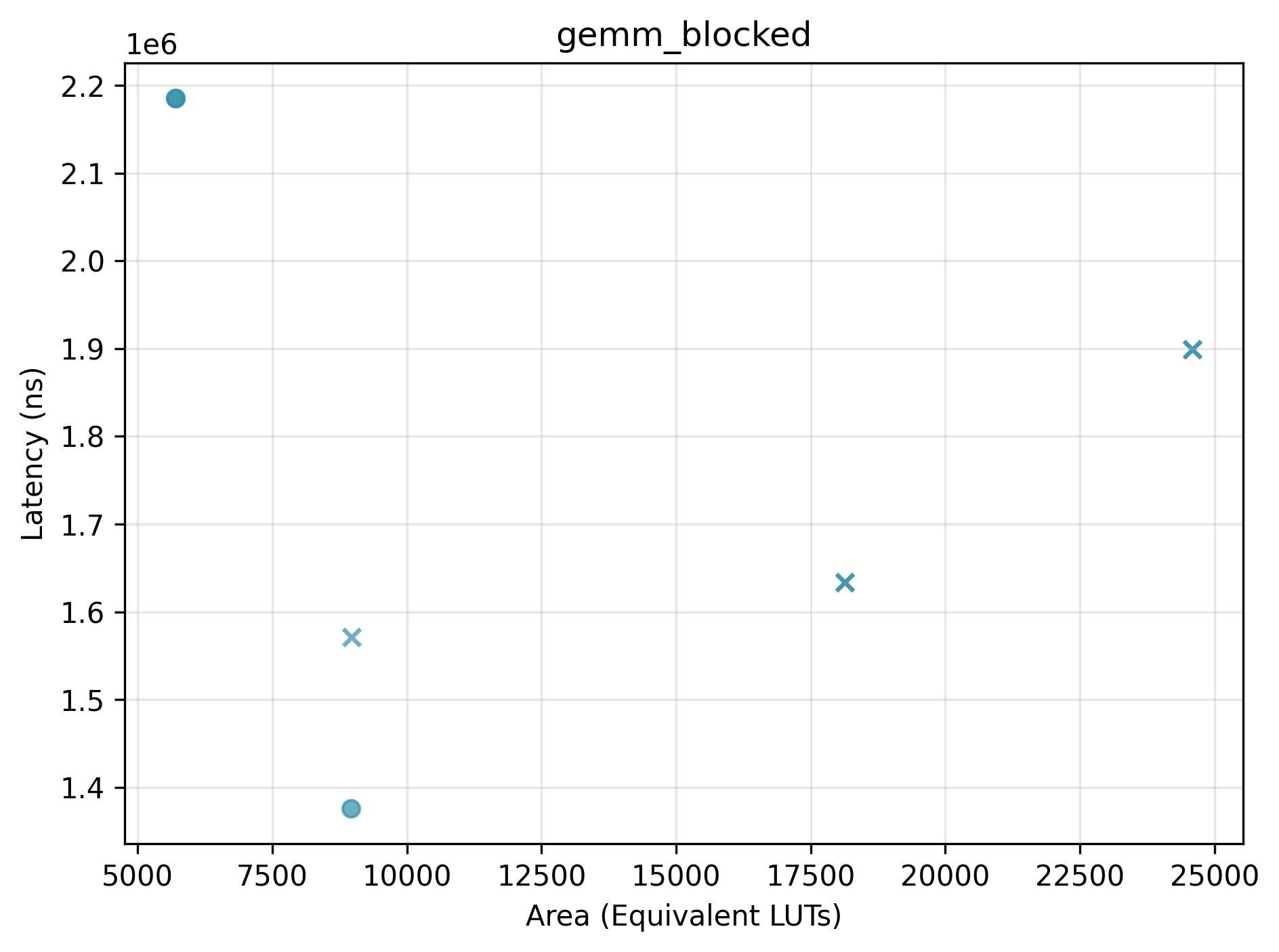
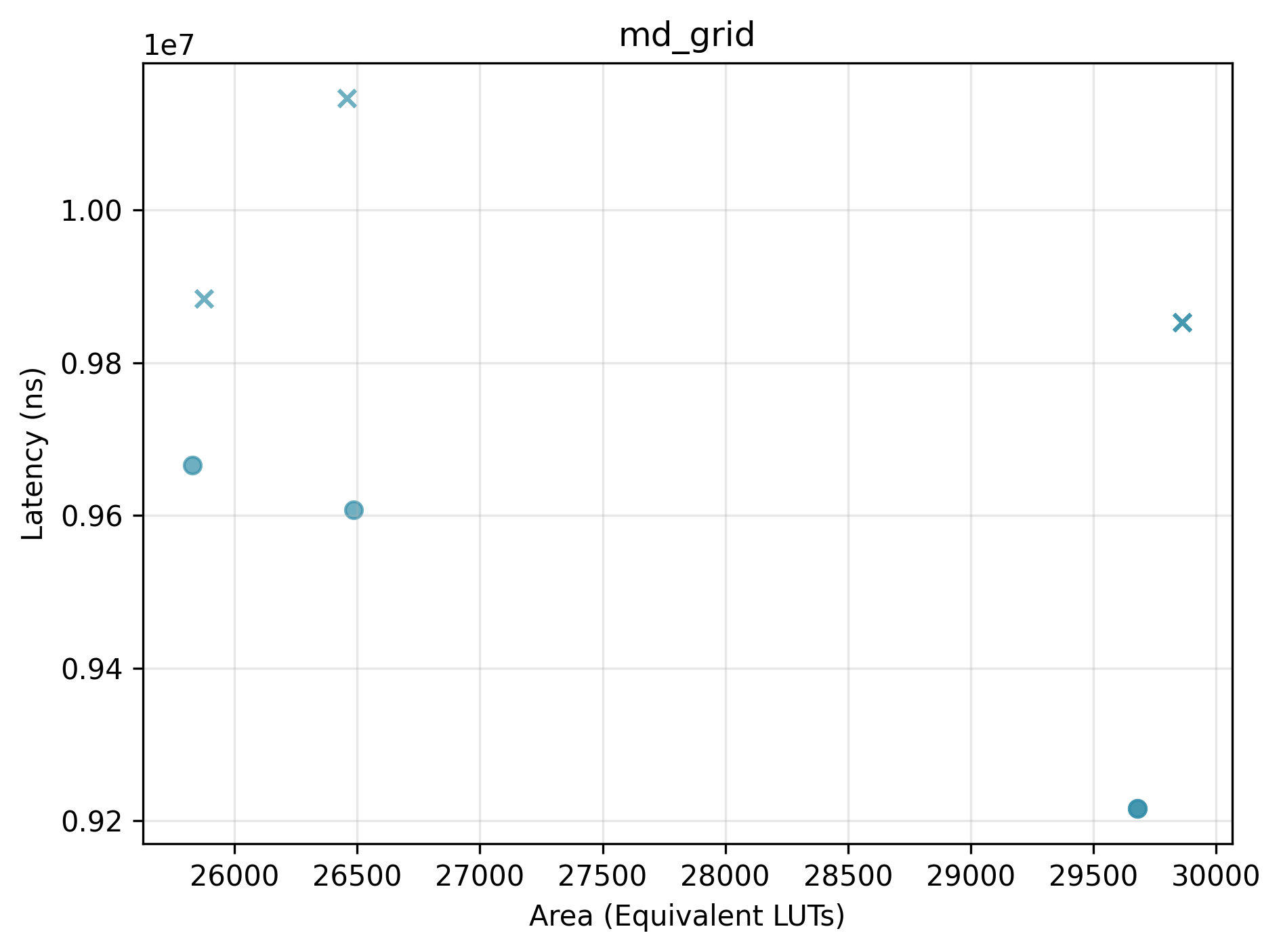
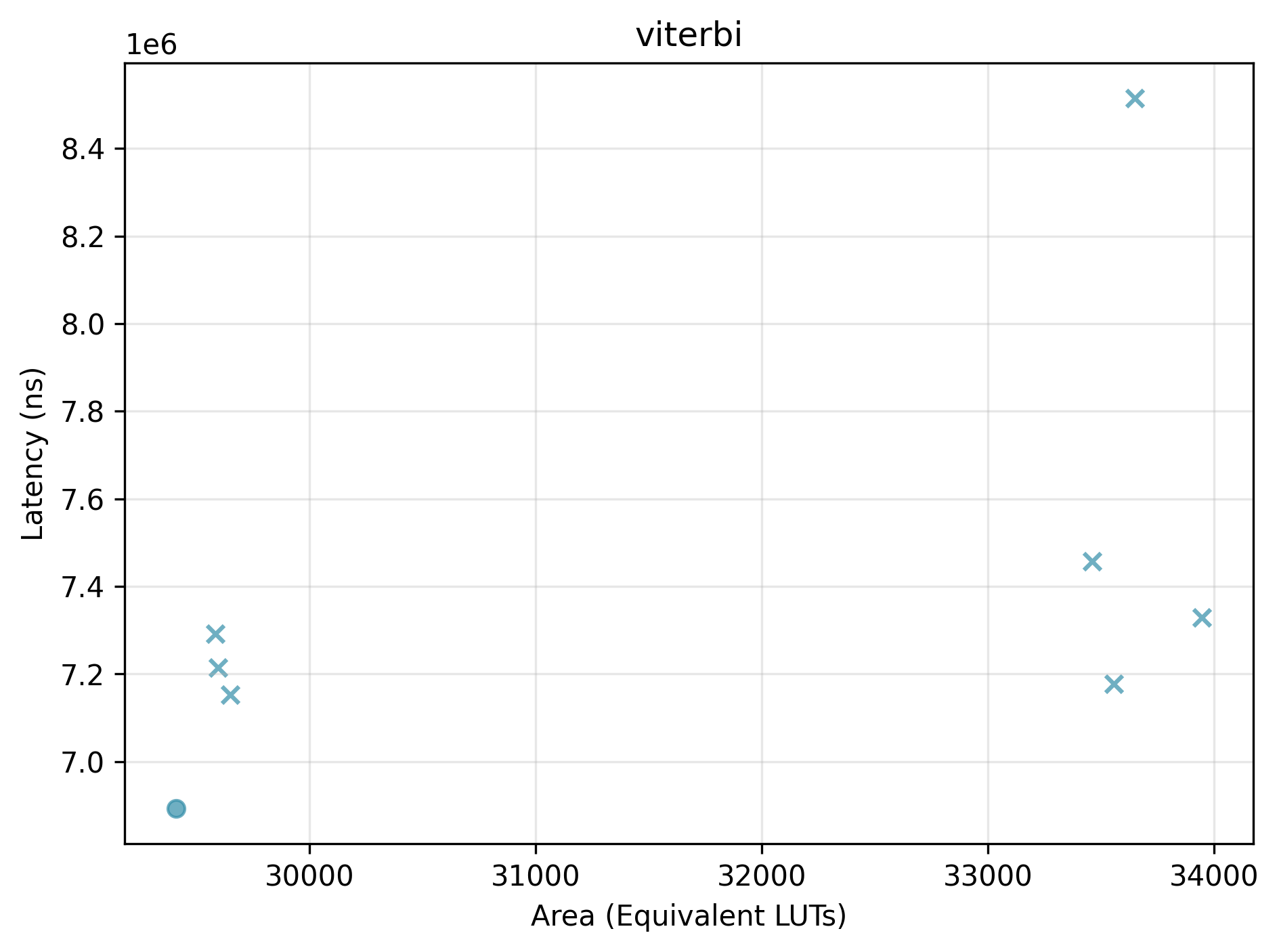
We highlight the effect of selecting different Bambu configuration options, which can steer Bambu towards different trade-offs between performance and area.
Pareto plots (Latency vs. Area) for selected benchmarks. Points marked with x are dominated.

Detailed Results
Post-p&r timing and area metrics for each benchmark and each selected configuration are available in a separate table.